

 "Data is so perfect," a drunk data scientist never said. Real-world data is so messy that not even ethanol intoxication could alter its reality. Processing of such data is well known for its quick delivery of "penthouse with a pool" type of nightmares in every partaker's subconsciousness. Sometimes, one hears consolation tunes with funny lyrics that spits lines such as "data processing is 80% while task like modelling, deployment, etc take the rest. Verily verily I say unto you with both hands raised and a refuting mouth "Pay them no mind titans, for data processing is 1hunnid and the rest is compensation that thy heart may still find the purpose for its beat! "
"Data is so perfect," a drunk data scientist never said. Real-world data is so messy that not even ethanol intoxication could alter its reality. Processing of such data is well known for its quick delivery of "penthouse with a pool" type of nightmares in every partaker's subconsciousness. Sometimes, one hears consolation tunes with funny lyrics that spits lines such as "data processing is 80% while task like modelling, deployment, etc take the rest. Verily verily I say unto you with both hands raised and a refuting mouth "Pay them no mind titans, for data processing is 1hunnid and the rest is compensation that thy heart may still find the purpose for its beat! "
But hey, there is HOPE. Today, we are going to discuss how to cut off one of many weaponized heads of real-world data aka Ratking. Dude goes by the name missing values. Street name claps so hard you sure he def ain't your regular gangster. Before we get started on tackling this enemy, let's understand what he is made of😎
What is Data?
Data can be referred to as facts and statistics collected together for reference or analysis. It can come in form of rows and columns (tabular data), images, videos, audio files, etc. Due to the method the data is being collected and collated, each form of data usually requires a peculiar approach for its efficient processing and subsequent extraction of information for real-world application. Now let's discuss these peculiar approaches with focus on tabular data.
What is data processing?
Data processing is a process of inspecting, cleansing, transforming and modelling data with the goal of discovering useful information, informing conclusion and supporting decision making. In simple terms, it is the act of putting our collected data in a format that makes extraction of information possible. In this article, we will focus on one of the numerous ways available for putting our data in the desired format: Handling missing values.

We will achieve this using python's pandas library. Pandas is a famous data handling and manipulation tool which uses DataFrame as its key data structure. It was built upon the Numpy package.
Why Pandas?
Pandas which stands for panel data offer data structures like DataFrame and series which is employed in manipulating numerical tables and time-series data. it is very efficient and got so many powerful functions/tools that greatly reduce the time-consuming process of data processing.
To demonstrate how we can handle missing values, we will be using the Zindi/DSN Kowope Mart dataset. Let's go ahead and import it along with necessary packages.
import pandas as pd
import numpy as np
# import our kowope dataset
kowope_df = pd.read_csv('./DSN_DATASET/Train.csv')
Next, we are going to glance through our dataset to understand it better
kowope_df.head()
kowope_df.describe()
kowope_df.info()
Based on the output, we noticed that some rows had the NaN value and some were also categorical. We can solve this issue by applying one or more of the following;
- fill with mean, median or mode of individual columns
- fill with dummy variables for the categorical columns
Filling with mean, median or mode of individual columns
#number of null values for each column
print(kowope_df.isnull().sum())
#print columns with their types
print(kowope_df.dtypes)
#drop categorical columns
non_cat_df = kowope_df.drop(['form_field47', 'default_status'], axis=1)
#calculate mean of all continuous value columns and fill the NaN values
non_cat_df.fillna(non_cat_df .mean())
#calculate median of all continuous value columns and fill the NaN values
non_cat_df.fillna(non_cat_df .median())
#calculate mode of all continuous value columns and fill the NaN values
non_cat_df.fillna(non_cat_df .mode())
Filling with dummy variables for the categorical columns
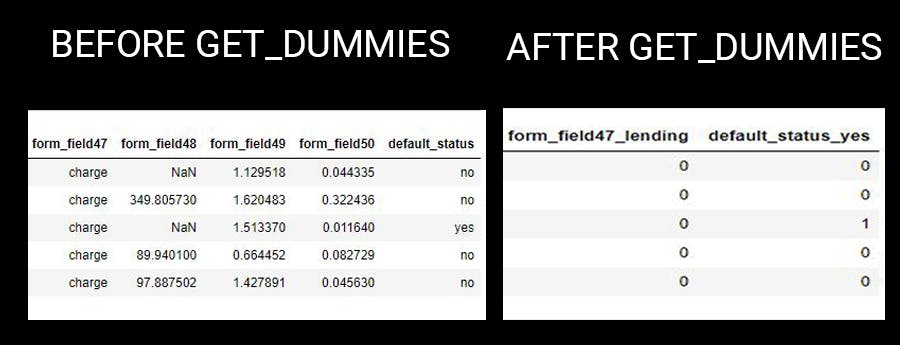
Since most algorithms can only work with numerical values, we will convert our categorical values to binary using pandas get_dummies function. This will create multiple columns, each representing individual categorical values where '1' indicates present at the sample and 0 otherwise.
#This will convert all the categorical columns to integers >= 0
#Then drop the first column to reduce repetition of columns
cat_cols = pd.get_dummies(kowope_df, drop_first=True)
Output
 In summary, missing values is one aspect of data processing that is very important and not taking care of it will most times affect the performance of the deployed model that the data was built upon. Happy coding !!!
In summary, missing values is one aspect of data processing that is very important and not taking care of it will most times affect the performance of the deployed model that the data was built upon. Happy coding !!!
PS: This is my first attempt at technical writing. Your constructive criticism is highly welcomed😊